Personal Restaurant Recommender
Recommendation systems are becoming increasingly essential for services such as Amazon, Netflix and Yelp due to growing amounts of users, products and data in general. These valuable and effective techniques reduce the choice set of products for users and present them instead with a finite number of choices that are more meaningful and uniquely tailored to the individuals interests.
A common difficulty encountered with recommendation systems is the issue of the cold start problem. Here the initial absence of data about a user results in general and non-specific recommendations. In order to create accurate recommendations large amounts of data for a user is often required. This can be achieved explicitly or implicitly. In both cases the cold start problem implies that the user has to dedicate some time using the system in its initial poor state in order to construct their user profile. Only after this will the system start providing intelligent recommendations.
Here I present an approach that overcomes this cold start problem by utilizing a persons twitter history. From this history home and work locations for the individual are inferred and meaningful restaurant recommendations can be immediately generated. The user data and restaurant recommendations are then visualized. Recommendations can be further tuned by adjusting the users sensitivity to distance, cost and restaurant rating.
Inferring Locations:
For each user a collection of their tweets were found. Guided by the work of Eunjoon Cho et al I worked on the observation that people show strong periodic behavior throughout certain periods of the day. This behavior alternates between "home" and "work" locations on weekdays. Depending on the time of the day movements will either be centered around home, work, or somewhere in between the two locations as they commute. I used a two mode Gaussian model showing that at any point in time a user is either in "home" or "work" state. The probability distribution over the state of the user over time was modeled with a truncated Gaussian distribution parameterized by the time of the day:
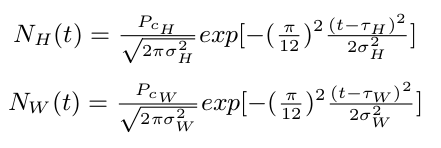
and then:
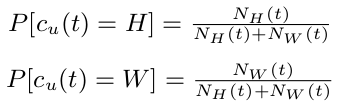
Here $\tau_{H}$ is the average time of the day when a user is at home and $\sigma_{H}$ is the variance in time of day. $P_{cH}$ is the time-independent probability that any given check-in was generated by the "home" state. The same holds true for the work state. Due to the cyclic nature of time the differences in the tweet time-stamp times were treated as an average of angles about a circle. Using this technique allows 11:59pm and 12:01am to be correctly modeled as being two minutes apart. Therefore $\tau_{H}$ and $\tau_{W}$ were calculated as an average of angles about a circle. A more in-depth explanation of this can be found by the paper from Eunjoon Cho et al .
Recommendations:
For each user in the database their home and work locations were inferred using the technique described above. For this work data from Twitter and Google locations was utilized. A visualization of these locations and the users tweets were generated.
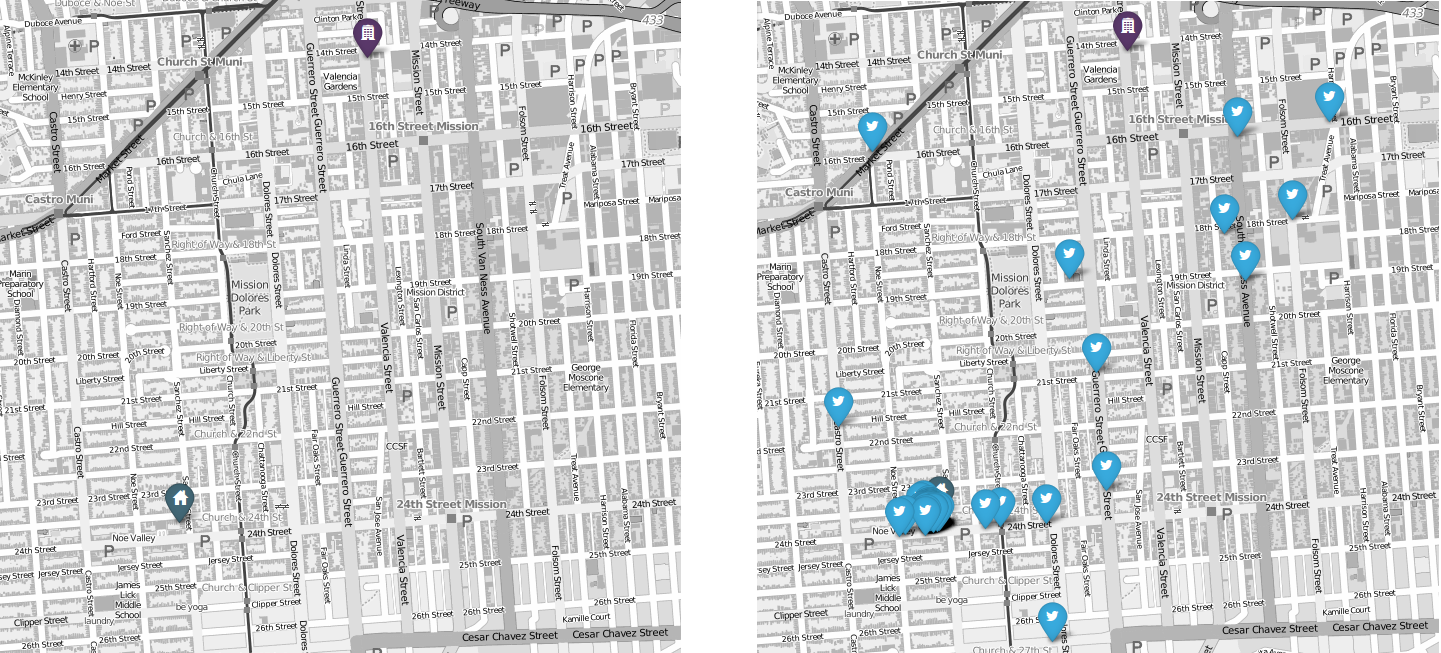
Recommendations were then generated for a user given the knowledge that they are in their home or work state. This recommendation is based on a linear combination of three features:
- Sensitivity to distance
- Sensitivity to cost
- Sensitivity to restaurant rating
The probability of an individual traveling to an area was calculated by the radiation model:
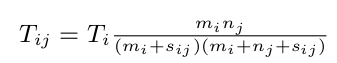
Here we consider locations $i$ and $j$ with population $m_{i}$ and $n_{j}$ respectively, at distance $r_{ij}$ from each other and denote $s_{ij}$ to be the total population in a circle of radius $r_{ij}$ centered at $i$. A heat-map of generated transition probabilities for an individual given that they are leaving their home is visualized below.
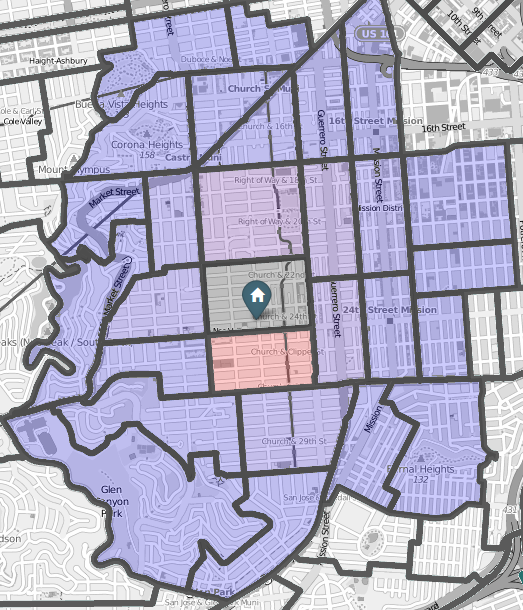
Here we can see the probability of a person at home visiting the surrounding areas. These probabilities are combined with the users sensitivity to distance when making recommendations. Meta data from restaurants was also used when generating recommendations. This information included the restaurant rating and value of money. Ratings assigned to each restaurant taking a value between 1 to 5 inclusive. Similarly a value of money rating is assigned to each restaurant taking a value between 1 and 4 inclusive. The persons sensitivity to these values are set by the sliding scale below.

In this work recommendations were made for a person by weighting each restaurant according to its distance from the user, its current five star rating and its rating for value of money. Shown below is the user input interface for this restaurant recommendation system.
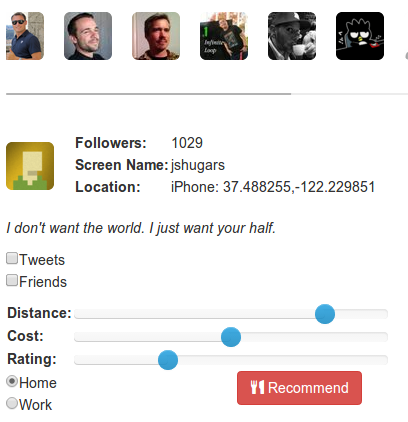
Here users can be selected from the list at the top. Descriptive statistics are displayed for each user showing their profile image, alias name and number of follows. Their self-described description is also provided. The users tweets and friends home locations can also be displayed. The sensitivity of the user to each of the three features is adjusted and recommendations are generated
Results:
An interactive demo of the systems can be found here. You can select users and explore the resulting recommendations for yourself. An static image of the final system is provided below.
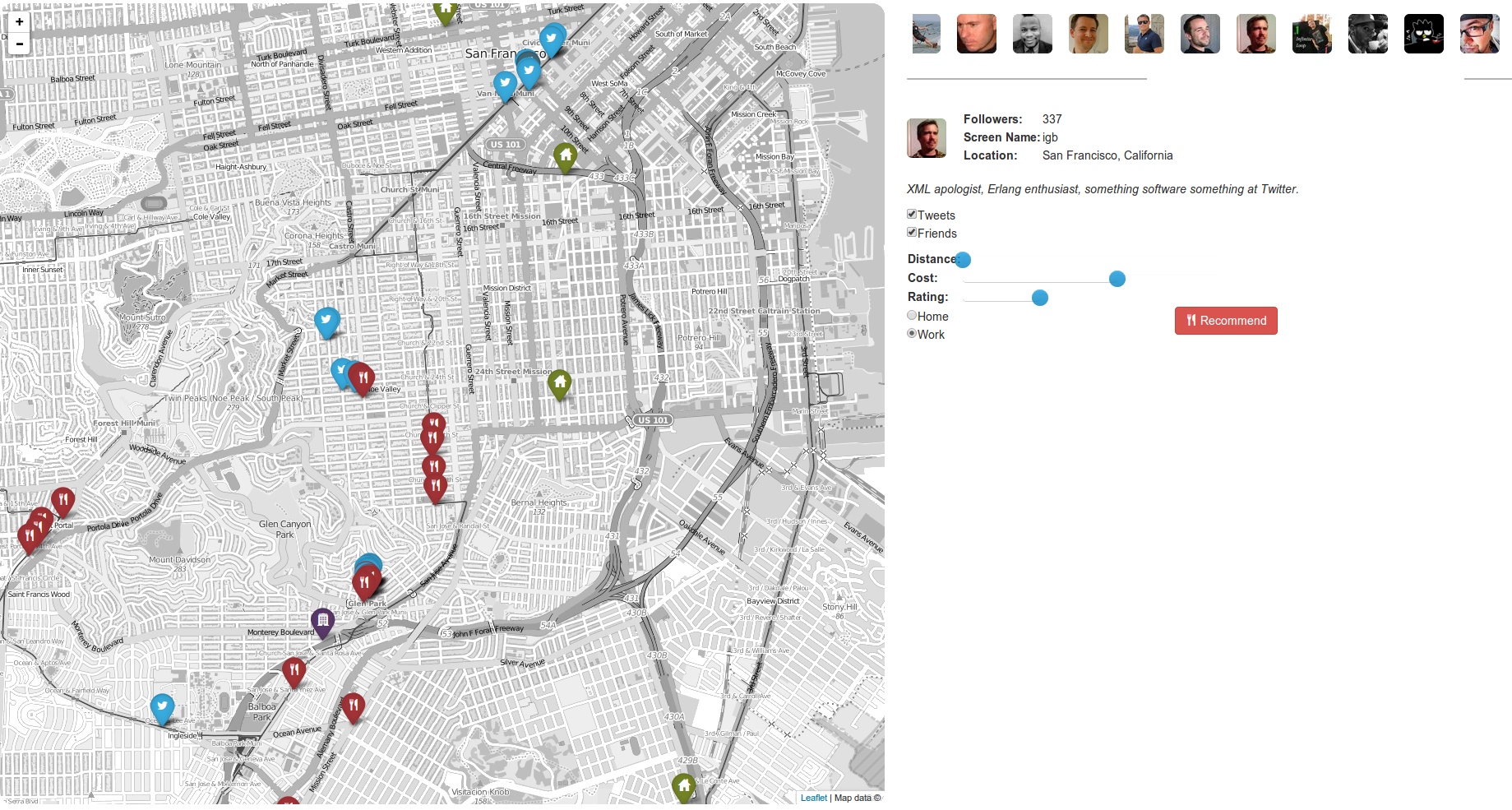
Conclusion and Future work:
As illustrated above this work makes personalized recommendations for an individual by taking an individuals home and work locations into account and weighting based on the users sensitivity to distance, cost and rating. Using twitter data home and work locations are inferred. Next personalized recommendations for restaurants were generated based on the users location and their sensitivity to travel distance, cost and restaurant rating. These recommendations don't require any explicit information form the user. The user of this system is immediately presented with intelligent recommendations that are personalized to the user. These results can be further personalized by adjusting the users sensitivity to distance, cost and rating.
While the current system makes accurate restaurant recommendations future work would look at inferring baseline sensitivities for each individual. These values can be inferred by looking at the sociodemographic characteristics of the areas where the user lives using information such as census data. Sensitivity to cost can be initially inferred by looking at the value of the area the individual lives and works. Sensitivity to distance can be initially inferred by looking at the distance of each tweet from the users home and place of work.
Additionally the temporal component of the recommendations should be automated or be allowed to be inputted to the recommender system. Currently recommendations are generated for the user being at home home or at work despite have the probabilities of being in each state given time.
Finally the influence of friendships should be included in the recommendation system. During the weekends the recommendation system could take into account areas likely to be visited by friends and include these in the recommendations by weighting based on strength of the friendships.